CSV to a query API in 60 seconds
The fastest path. Point Indexa at a CSV; if the columns already match an entity, no handler is needed.
Write the config
One file describes the source, the target, and your entities.
name: orders-indexer
source:
type: csv
sources:
- { key: orders, file: data/orders.csv }
target:
type: sqlite
path: ./orders.db
schema:
Order:
id: ID
customer: String
total: BigDecimal
status: String
items: IntDeploy
$ indexa deploy --config indexa.config.yaml
INFO [cli:engine] setup complete {source:"csv", streams:["orders"]}
INFO [cli] query API listening {url:"http://localhost:4000"}
INFO [cli:engine] indexed batch {stream:"orders", count:6, cursor:"6"}Query
$ curl "localhost:4000/orders?status=paid&orderBy=items&desc=true"
Auto-mapping. Because the CSV columns match the Order entity (case/plural-insensitive), Indexa coerces each field to its declared type and writes it. No handler required.
Tail a Postgres table
Change-data-capture without the moving parts. The connector tails a table by a monotonic cursor column and resumes exactly where it left off.
Configure the source
source:
type: postgres
connection: ${SOURCE_DB_URL}
tables:
- { key: orders, table: orders, cursorColumn: updated_at }The cursorColumn must be monotonically increasing (an updated_at timestamp or a serial id). That is what lets the engine resume without rescanning.
Use Postgres as the target too
For production, write to Postgres (requires npm install pg). Tables are created automatically from your schema.
target:
type: postgres
connection: ${DB_URL}Index on-chain events
You don't write engine code, RPC plumbing, or reorg handling. Declare a contract, ABI, and events; write a short handler per event; deploy.
The full source config
source:
type: evm
rpc: ${RPC_URL} # an Alchemy/Infura/QuickNode HTTPS endpoint
confirmations: 12 # blocks behind head before indexing (reorg safety)
blockBatchSize: 2000 # max block span per eth_getLogs call
reorgWindow: 128 # how deep a reorg we can still roll back
contracts:
- address: "0xA0b86991c6218b36c1d19D4a2e9Eb0cE3606eB48"
abi: ./erc20.abi.json
events: [Transfer]
startBlock: 18000000
Write a handler
Each event is a stream named after the event. Indexa decodes the log; you receive event.args by name. Large integers arrive as strings to preserve precision.
export default {
async Transfer(event, ctx) {
const { from, to, value } = event.args;
await ctx.store.upsert('Transfer', event.id, {
id: event.id, from, to, value: String(value),
blockNumber: event.blockNumber, txHash: event.txHash,
});
const v = BigInt(value);
await adjust(ctx, from, -v); // read-modify-write
await adjust(ctx, to, +v);
},
};
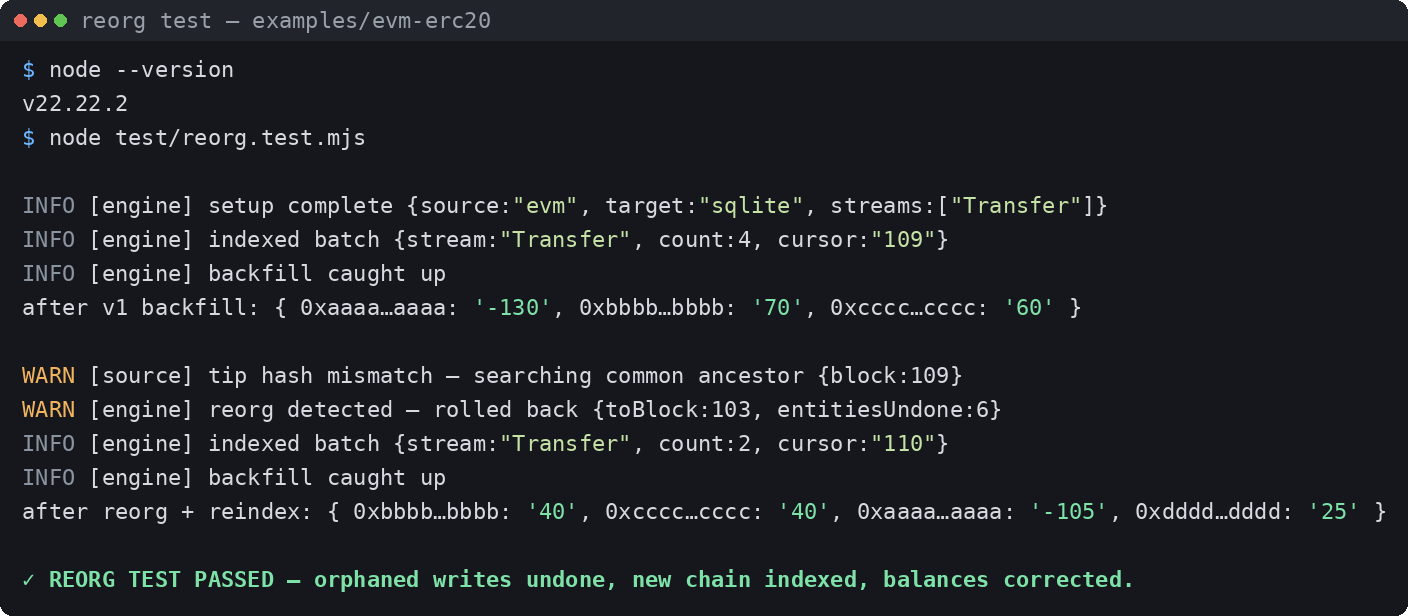
Reorgs are handled for you
Every write made while indexing an unfinalized block is recorded in an undo journal. When the connector detects a changed tip hash, it walks back to the last common ancestor, undoes orphaned writes — including aggregated balances — and re-indexes the new canonical chain, all in one transaction.
Operations checklist
startBlock = the contract deploy block (don't use 0).confirmations matches your chain's finality (mainnet ~12; tune L2/sidechains).reorgWindow ≥ the worst-case reorg depth you want to survive.blockBatchSize if your provider rejects wide ranges. Use an archive node only if a handler reads historical state.Write your own connector
Kafka, Firehose, a non-EVM chain — anything that exposes ordered records with a monotonic cursor. Implement three methods, register, deploy.
export default class KafkaConnector {
async init(config, { logger, kv }) { /* connect, restore state from kv */ }
async streams() {
return [{
key: 'events',
reorgAware: false, // set true for chains; return { reorg }
async fetchBatch(fromCursor, size) {
const records = await pull(fromCursor, size);
return { records, done: records.length < size };
},
}];
}
async close() { /* disconnect */ }
}
Register it before deploy:
import { registerConnector } from 'indexa';
import KafkaConnector from './kafka-connector.js';
registerConnector('kafka', KafkaConnector);
For reorg-aware streams, set reorgAware: true and return { reorg: { toCursor } } when you detect one — the engine handles rollback via the journal. You can also inject a transport for testing, exactly how the reorg test simulates a whole chain without a node.